23 / 05 / 13
使用机器学习算法实现Web攻击检测 - 项目分析

author: Nacht
date: 2023-05-13
本文由晚晚投稿,全文共7800字,预计阅读时间20分钟。
目录
-
全项目分析
-
项目结构
-
源码解析
-
core.py
-
导入部分
-
正常请求和恶意请求获取
-
(被注释)正常请求和恶意请求获取并去重
-
文本预处理
-
将处理后的文本转化为向量
-
生成X和Y
-
(被注释)使用SVM算法对训练数据集进行交叉验证
-
(被注释)使用KNN算法对训练数据集进行交叉验证
-
使用朴素贝叶斯算法对训练数据集进行交叉验证
-
(被注释)查看朴素贝叶斯算法分类错误的样本
-
-
demo.py
-
导入部分(和core.py类似)
-
正常请求和恶意请求获取(和core.py类似)
-
文本预处理(和core.py类似,但没有测试打印内容)
-
将处理后的文本转化为向量(和core.py类似)
-
生成X和Y矩阵(使用了相对core.py来说更高效的方式 - 仅对于较少的数据量来说)
-
使用朴素贝叶斯算法对训练数据集进行交叉验证(类似于core.py,但修改了输出格式)
-
构造测试请求
-
使用训练好的分类模型对测试数据进行预测
-
输出预测结果
-
-
count.py
-
getNormalPara.py
-
导入部分
-
提取文件中所有链接的参数值并保存到列表中
-
将提取出的参数值写入文件
-
-
makeChar.py
-
removeRepeat.py
-
导入部分将字符串去重并添加到列表中(putInList函数)
-
从文件中读取数据、去重并分别存入正常请求/恶意请求列表中(removeInFile函数)
-
-
reptile.py
-
导入部分定义基础列表获取单个页面(getPageLink函数)
-
判断页面是否属于某个域名(ifBelong函数)
-
获取单个域名(getThisDomain函数)
-
循环取出全部域名内容
-
-
try.py
-
wordProcess.py
-
导入部分读取关键词列表并将关键词生成数组将字符串转化为特征向量(changePayload函数)
-
将文档(训练样本)转化为词集模型向量(wordToVec函数)
-
创建文本训练集向量(createDocVec函数)
-
将文本按照长度进行分类(getWords函数)
-
判断文本是否是非常规字符(isStrangeChr函数)
-
-
-
项目结构
首先,项目结构如下:
. ├── ipynb/ ├── save/ ├── src/ ├── venv/ ├── core.py ├── count.py ├── demo.py ├── getNormalPara.py ├── makeChar.py ├── removeRepeat.py ├── removeRepeat.pyc ├── reptile.py ├── requirements.txt ├── try.py ├── wordProcess.py └── wordProcess.pyc
其中,目录部分有:
-
ipynb/:存放jupyter notebook相关文件(可看作在运行时上可以直接运行的代码)。 -
save/:存放部分存档数据。(不重要) -
src/:存放存储资源(也就是那些代码中需要用到的文件,比如恶意载荷和正常请求等)。 -
venv/:python虚拟环境目录。(不重要)
源码部分有(注:.pyc是.py经过编译后生成的字节码文件,不额外解释):
-
core.py:使用机器学习算法对请求进行分类,并且交叉验证模型的准确度。 -
count.py:从指定文件读取正常请求和恶意请求,去重后分别输出正常请求和恶意请求的数量。 -
demo.py:使用特定数据集评估模型准确率,并使用模型对数据集中的请求进行分类。 -
getNormalPara.py:从指定文件中提取所有链接,并且从链接中提取参数值,最终写入文本文件。 -
makeChar.py:打印出ASCII 码表中除了数字、大小写字母和英文符号之外的所有字符。 -
removeRepeat.py:读取正常请求和恶意请求并且去重,最后返回一个字典对象。 -
reptile.py:根据指定的域名/链接列表进行模拟访问,最终列出所有已访问的域名/链接。 -
try.py:纯粹的测试文件,测试将字符串 b 中所有出现的字符串 a 替换为字符常量 z。 -
wordProcess.py:对文本进行处理,包括:-
从文件中读取关键词列表。
-
将恶意载荷转换为向量并创建文本训练集向量。
-
对恶意载荷进行特征提取,并且返回一个包含所有提取出来的特征列表。
-
杂项文件有:
requirements.txt:项目需求档,用于pip对环境进行构建。
源码解析
总体来说,主要执行文件包括core.py和demo.py。
其余工具类源码/库源码包括count.py、getNormalPara.py、makeChar.py、removeRepeat.py、reptile.py、try.py以及最重要的wordProcess.py。
core.py
分两个大部分~分别是未注释的部分和有注释的部分。
导入部分
from operator import * import numpy as np from sklearn.cross_validation import train_test_split from sklearn import svm from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import MultinomialNB from sklearn.cross_validation import cross_val_score
这里主要导入了下面的内容:
-
operator:提供一系列常见的数据类型的运算符,如加法、减法、比较等。 -
numpy:Python 中用于科学计算的核心库,支持高性能的多维数组和矩阵运算。 -
train_test_split:scikit-learn 库中用于将数据集划分为训练集和测试集的函数。 -
svm: scikit-learn 库中用于支持向量机算法的模块。 -
KNeighborsClassifier: scikit-learn 库中用于 k 近邻算法的分类器。 -
MultinomialNB: scikit-learn 库中用于多项式朴素贝叶斯分类器的类。 -
cross_val_score: scikit-learn 库中用于交叉验证的函数。
import wordProcess as wp import removeRepeat as rr
另外,还导入了接下来的两个自定义模块,分别是wordProcess.py和removeRepeat.py。
分别用于文本处理和文本去重。
正常请求和恶意请求获取
res = wp.getWords(0) norm_list = res['normal'] pl_list = res['payload']
这部分主要通过调用wordProcess.py中的getWords 函数,从文件中读取正常请求和恶意请求(payload),并将读取到的正常请求与恶意请求转换为列表形式。
(被注释)正常请求和恶意请求获取并去重
res = rr.removeInFile("./src/normal_require.txt","./src/payload.txt") norm_list = res['normal'] pl_list = res['payload']
类似于“正常请求和恶意请求获取”,但调用的是removeRepeat.py中的去重导入方法。
文本预处理
payloads = [] for pl in pl_list: payloads.append(wp.changePayload(pl)) requires = [] for req in norm_list: requires.append(wp.changePayload(req)) print payloads[104] print pl_list[104]
通过调用wordProcess.py中的changePayload函数,将输入的请求文本(原先列表中的内容)进行一系列的处理,并将其放入新的列表中。随后打印出转化后的内容(payloads[104])和原始内容(pl_list[104])。
将处理后的文本转化为向量
vec_list = wp.createDocVec(payloads,requires) payloads_vec = [] requires_vec = [] for payload in payloads: payloads_vec.append(wp.wordToVec(vec_list,payload)) for require in requires: requires_vec.append(wp.wordToVec(vec_list,require)) payloads_vec = np.array(payloads_vec) requires_vec = np.array(requires_vec)
调用wordProcess.py中的createDocVec函数,创建文本向量列表。
然后,通过for循环调用wordToVec函数进行文本向量转换,将得到的向量列表分别存储在requires_vec和payloads_vec中。
最后调用numpy的array函数,将两个列表转换为numpy列表以便后续计算。
生成X和Y
X = np.concatenate((payloads_vec,requires_vec)) Y = [] for i in range(0,len(payloads_vec)): Y.append(1) for i in range(0,len(requires_vec)): Y.append(0)
调用numpy中的concatenate函数将之前生成的向量表示拼接在一起(正常请求和恶意请求),生成完整的输入特征矩阵X。
随后利用for循环生成相应的标签列表Y(注:Y是一维列表),以得到完整的数据集。
- 其中,所有恶意请求向量的标签为1,正常请求向量的标签为0。
(被注释)使用SVM算法对训练数据集进行交叉验证
clf = svm.SVC(kernel='sigmoid') scores = cross_val_score(clf, X,Y, cv=10, scoring='accuracy') print scores print scores.mean()
实例化一个svm.SVC对象(支持向量机对象),并且将函数设为Sigmoid核(一种常用的核函数)。
- 这里不详细介绍Sigmoid核,但是给出一个基础形式:
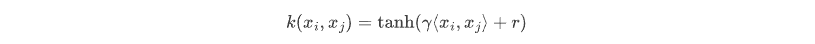
其中,$\gamma$ 和 $r$ 是需要调节的参数,$\lang{x_i},{x_j}\rang$表示两个向量的内积。
Sigmoid核函数将输入向量 $x_i$ 和 $x_j$ 映射到一个相对低维的特征空间,并且计算它们的相似度,从而构建出最优超平面并实现数据分类。
(被注释)使用KNN算法对训练数据集进行交叉验证
knn = KNeighborsClassifier(n_neighbors=4) scores = cross_val_score(knn, X,Y, cv=10, scoring='accuracy') # for classification print scores print scores.mean() k_range = range(1, 10) k_scores = [] for k in k_range: knn = KNeighborsClassifier(n_neighbors=k) scores = cross_val_score(knn, X,Y, cv=10, scoring='accuracy') # for classification k_scores.append(scores.mean()) print k_scores
实例化一个KNeighborsClassifier 类对象,并且将近邻数设为 4。
- 近邻数对KNN来说是一个很重要的参数,用于控制算法的性能和复杂度。近邻数越小,模型对训练数据的拟合程度越高,但同时也容易出现过拟合;而近邻数越大,模型则更加平滑,泛化能力也更强,但可能会导致欠拟合。
然后,调用cross_val_score函数对模型进行交叉验证,得到多轮的验证结果并计算平均值。
第四行和第五行的内容并不用于KNN算法,仅仅打印出之前SVM的交叉验证结果以及平均值。
k_range = range(1, 10)用于设置一个1~10的整数序列,用于遍历不同的近邻数。
下面的for循环则用于:
-
实例化一个KNN模型对象(使用
KNeighborsClassifier)方法。 -
调用
cross_val_score对模型进行交叉验证,并将验证结果的平均值添加到k_scores中。
最后打印出1~10近邻数下的验证结果,以确定近邻数设置为多少时模型的准确率最高。
使用朴素贝叶斯算法对训练数据集进行交叉验证
clf = MultinomialNB() clf.fit(X,Y) for i in range(len(X)): temp = np.array(X[i]).reshape((1,-1)) if(clf.predict(temp)[0] != Y[i]): if i < len(pl_list): print "payload 分类错误" print pl_list[i] print payloads[i] else: print "正常请求分类错误" print norm_list[(i-len(pl_list))] print requires[(i-len(pl_list))] print "\n"
使用MultinomialNB()函数实例化一个对象,作为朴素贝叶斯模型。
调用fit方法,使用特定数据进行训练。
随后遍历所有样本,将每个样本的特征向量输入模型进行预测,并与其真实标签进行比较。(判断有没有正确分类)
如果没有被正确分类,那么就再判断该样本是恶意请求还是正常请求,然后打印出是正常请求被分类错误还是恶意请求被分类错误。
demo.py
导入部分(和core.py类似)
from operator import * import numpy as np from sklearn.cross_validation import train_test_split from sklearn import svm from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import MultinomialNB from sklearn.cross_validation import cross_val_score
这里主要导入了下面的内容:
-
operator:提供一系列常见的数据类型的运算符,如加法、减法、比较等。 -
numpy:Python 中用于科学计算的核心库,支持高性能的多维数组和矩阵运算。 -
train_test_split:scikit-learn 库中用于将数据集划分为训练集和测试集的函数。 -
svm: scikit-learn 库中用于支持向量机算法的模块。 -
KNeighborsClassifier: scikit-learn 库中用于 k 近邻算法的分类器。 -
MultinomialNB: scikit-learn 库中用于多项式朴素贝叶斯分类器的类。 -
cross_val_score: scikit-learn 库中用于交叉验证的函数。
import wordProcess as wp import removeRepeat as rr
另外,还导入了接下来的两个自定义模块,分别是wordProcess.py和removeRepeat.py。
分别用于文本处理和文本去重。
正常请求和恶意请求获取(和core.py类似)
res = wp.getWords(0) norm_list = res['normal'] pl_list = res['payload']
这部分主要通过调用wordProcess.py中的getWords 函数,从文件中读取正常请求和恶意请求(payload),并将读取到的正常请求与恶意请求转换为列表形式。
文本预处理(和core.py类似,但没有测试打印内容)
payloads = [] for pl in pl_list: payloads.append(wp.changePayload(pl)) requires = [] for req in norm_list: requires.append(wp.changePayload(req))
通过调用wordProcess.py中的changePayload函数,将输入的请求文本(原先列表中的内容)进行一系列的处理,并将其放入新的列表中。
将处理后的文本转化为向量(和core.py类似)
vec_list = wp.createDocVec(payloads,requires) payloads_vec = [] requires_vec = [] for payload in payloads: payloads_vec.append(wp.wordToVec(vec_list,payload)) for require in requires: requires_vec.append(wp.wordToVec(vec_list,require)) payloads_vec = np.array(payloads_vec) requires_vec = np.array(requires_vec)
调用wordProcess.py中的createDocVec函数,创建文本向量列表。
然后,通过for循环调用wordToVec函数进行文本向量转换,将得到的向量列表分别存储在requires_vec和payloads_vec中。
最后调用numpy的array函数,将两个列表转换为numpy列表以便后续计算。
生成X和Y矩阵(使用了相对core.py来说更高效的方式 - 仅对于较少的数据量来说)
X = np.concatenate((payloads_vec, requires_vec)) Y = [1] * len(payloads_vec) + [0] * len(requires_vec)
调用numpy中的concatenate函数将之前生成的向量表示拼接在一起(正常请求和恶意请求),生成完整的输入特征矩阵X。
随后利用计算生成Y(注:Y是一维列表),以得到完整的数据集。
- 其中,所有恶意请求向量的标签为1,正常请求向量的标签为0。
# 其中,Y构造相当于 Y = [1] * len(payloads_vec) + [0] * len(requires_vec) # 这种for循环构造(效果相同) Y = [] for i in range(0,len(payloads_vec)): Y.append(1) for i in range(0,len(requires_vec)): Y.append(0)
使用朴素贝叶斯算法对训练数据集进行交叉验证(类似于core.py,但修改了输出格式)
clf = MultinomialNB() scores = cross_val_score(clf, X, Y, cv=10, scoring='accuracy') print("Accuracy: %.2f%% (+/- %.2f%%)" % (scores.mean() * 100, scores.std() * 2))
前两行代码使用MultinomialNB()函数实例化一个对象,作为朴素贝叶斯模型。然后调用 cross_val_score 函数对模型进行交叉验证,得到多轮验证结果并计算平均值。
输出则修改为格式化输出平均准确率和标准差,并指定精度为两位小数。
最终的输出看起来会像:Accuracy: 99.02% (+/- 0.05%)。
构造测试请求
test_requests = [ "SELECT Super_priv FROM mysql.user WHERE user=(SELECT user) LIMIT 1,1--", "SELECT Super_priv FROM mysql.user WHERE user='root' LIMIT 1,1--", "SELECT table_name, column_name FROM information_schema.columns WHERE table_schema='tblUsers'", "SELECT table_schema, table_name FROM information_schema.columns WHERE column_name='username'", "?vulnerableParam=-99 OR IF((ASCII(MID(({INJECTON}),1,1))=100),SLEEP(14),1)=0 LIMIT 1--", "id=1/*!uNIon*/SeLeCt+1,2,3--", "id=/*!UnIoN*/+/*!SeLecT*/+1,2,concat(/*!table_name*/)+FrOm/*!information_schema*/.tables/*!WhErE*/+/*!TaBlE_sChEMa*/+like+database()--", "mm_26632322_6858406_35042231", "3", "0a6717120000580d7379168400616436", "http%3A%2F%2Fwww.hao123.com%2F%3Ftn%3D96608247_hao_pg", "3", "0a6717120000580d7379168400616436", "acookie_id", "gnARD4e%2Byk4CAW8AAPzRV%2FtV", "tokenid", "gnARD4eyk4CAW8AAPzRVtVmmCqpjrpQn", "3AKJi", "null", "null", "1 || (select user from users where user_id = 1) = 'admin'", "1 || substr(user,1,1) = lower(conv(11,10,36))", "1 || substr(user,1,1) = unhex(61)", "1 || substr(user,1,1) = lower(conv(10,10,36))" ] random.shuffle(test_requests)
这部分主要构建一个用于测试的数据集。
数据集中有正常请求,也有异常请求,最后使用random.shuffle函数打乱顺序。
使用训练好的分类模型对测试数据进行预测
processed_requests = [] for req in test_requests: processed_requests.append(wp.changePayload(req)) X_test = [] for req in processed_requests: X_test.append(wp.wordToVec(vec_list, req)) X_test = np.array(X_test) clf.fit(X, Y) Y_pred = clf.predict(X_test)
首先,使用for训练遍历整个请求列表,对请求列表中的请求进行转化(调用wordProcess.py中的changePayload函数),并将转化后的请求保存到新的列表processed_requests中。
随后,遍历processed_requests,将其中的内容转化为特征向量(调用wordProcess.py中的wordToVec函数),并将转化后的内容输入到新的列表X_test中。
最后,将X_test转换为Numpy数组,对前两步创建的朴素贝叶斯分类器执行下面两项操作:
-
调用
fit函数,对上面创建的朴素贝叶斯分类器进行训练。 -
调用
predict函数进行分类预测,得到所有测试数据集的分类标签,并保存到Y_pred这个一维列表中。- 列表中的第
i个元素就代表第i个测试请求的预测结果。
- 列表中的第
输出预测结果
for i, req in enumerate(test_requests): if Y_pred[i] == 1: print("\033[38;2;139;0;0mTest request %d (%s) is malicious.\033[0m" % (i+1, req)) else: print("Test request %d (%s) is normal." % (i+1, req))
使用enumerate函数遍历所有测试请求,并判断其对应的预测标签是否为1(即是否为恶意请求)。
-
如果是,则打印输出红色文本提示该请求为恶意请求。
-
如果不是,则打印输出正常请求。
其中"\033[38;2;139;0;0m" 表示设置颜色为深红色,\033[0m 表示重置颜色到默认状态。
count.py
import removeRepeat res = removeRepeat.removeInFile("./src/normal_require.txt","./src/payload.txt") print "正常数量" print len(res['normal']) print "payload数量" print len(res['payload'])
非常简单的一个计算脚本。
调用removeRepeat.py中的removeInFile函数对指定目录下的文本进行去重,并且统计不同类型的数量。最后打印去重后两个列表的长度,具体流程如下:
-
读取
normal_require.txt和payload.txt两个文本文件中的数据。 -
将这些数据去重后分别存储在两个列表中。(之后讲
removeRepeat.py的时候会提到) -
使用
print打印出两个列表的长度,分别对应正常请求和 payload 的数量。
**
getNormalPara.py**
导入部分
from operator import * import re import urllib import types
导入了下面的内容:
-
operator:提供了 Python 内置运算符的对应函数,如加法、乘法、比较等。 -
re:用于进行正则表达式匹配操作。 -
urllib:包含了许多有用的 URL 处理函数,如解析 URL、编码/解码 URL 参数等。 -
types:定义了一些标准类型对象(如列表、字典、函数等)的名称。
提取文件中所有链接的参数值并保存到列表中
f = open('src/ff_12052236.html') links = [] linkPattern = re.compile(r'(href=".*?\")') for line in f.readlines(): links = linkPattern.findall(line) paras = [] paraPattern = re.compile(r'(\=.*?&)') for link in links: link = link[6:-1] paraList = paraPattern.findall(link) for para in paraList: paras.append(para[1:-5]) print len(paras)
首先,使用open函数打开名为ff_12052236.html的文件。
然后,定义一个正则表达式 linkPattern,用于匹配所有链接(即以 href= 开头的字符串)。
接着遍历文件中的每一行,使用 findall 函数查找所有链接,并在最后将结果保存到 links 中。
在获取了所有链接后,需要进一步提取其中的参数值,因此定义了另一个正则表达式paraPattern,用于匹配链接中的参数部分(即以 = 开头、以 & 结尾的字符串)。
-
对于每个链接,先将其修剪去除多余的字符,然后使用
findall方法查找其中的所有参数值,并将结果保存到paraList中。 -
例如
https://g.alicdn.com/ali-mod/aliyun-lego-console-ad/0.0.14/index.js?_=1480948524583最终会提取成为['1480948524583'](在去除首尾符号后)。
最后,遍历所有参数值,利用切片将其去掉首尾的符号后保存到 paras 列表中,并打印出paras列表中元素的数量。
将提取出的参数值写入文件
output = open('src/ff_temp.txt', 'w') for para in paras: if (len(para) > 0): output.write(urllib.unquote(para)) output.write('\n') output.close() f.close()
使用open函数创建一个文件对象output,并指定其打开方式为写入模式(即 'w')。
然后,遍历列表 paras 中的每个元素并进行判断:
-
如果长度大于0,则使用
urllib.unquote函数对其进行 URL 解码,并将结果写入到文件中。 -
如果长度为0,则不做任何事情,进入下一次循环。
最后,关闭文件对象和输入文件对象(在上一部分定义的)。
makeChar.py
#encoding:utf for ascii in range(0,126): if(ascii>31 and ascii<48 or ascii>57 and ascii<65 or ascii>90 and ascii < 95 or ascii>95 and ascii<97 or ascii>122): print chr(ascii) print ascii
简单的测试用文件,遍历 ASCII 码表中从 0 到 126 的所有字符,并输出其中属于符号类别(即除了数字、字母和空格之外的字符)的字符和对应的 ASCII 码值。
removeRepeat.py
导入部分
from operator import * import urllib
-
operator:包含一组对应于 Python 内置运算符的函数,用于进行数值计算、列表排序等操作。 -
urllib:包含URL 处理函数,用于处理 Web 应用程序中的 URL 请求和响应。
将字符串去重并添加到列表中(putInList函数)
def putInList(word,list): if word in list: return -1 else: list.append(word) return 1
首先,这个函数接收两个参数:一个字符串 word 和一个列表 list。
函数将使用条件语句判断字符串 word 是否已经存在于列表 list 中:
-
如果存在,则不进行任何操作,直接返回
-1。 -
如果不存在,则将字符串
word添加到列表list中,并返回1。
从文件中读取数据、去重并分别存入正常请求/恶意请求列表中(removeInFile函数)
def removeInFile(normalFile,payloadFile): fn = open(normalFile) fp = open(payloadFile) listNormal = [] listPayload = [] for line in fn.readlines(): putInList(line,listNormal) for line in fp.readlines(): putInList(line,listPayload) return { 'normal':listNormal, 'payload':listPayload }
首先,这个函数接收两个参数:一个正常请求文件路径 normalFile 和一个攻击流量文件路径 payloadFile。
使用 open 函数打开两个文件,并分别创建文件对象 fn 和 fp。
接着,创建两个空列表 listNormal 和 listPayload,用于保存从文件中读取到的数据。
随后使用for循环遍历文件对象 fn 中的每一行,并调用上面定义的函数 putInList 将其添加到列表 listNormal 中,putInList函数会确保列表中不存在重复的元素。对fp也采用类似的方式将内容添加到列表listPayload中。
最后,将两个列表打包成一个字典并返回,字典中包含两个键值对:
-
'normal'对应的值为从正常请求文件中去重后得到的列表。 -
'payload'对应的值为从攻击流量文件中去重后得到的列表。
reptile.py
导入部分
import requests
requests: Python 中常用的 HTTP 请求库之一,用于实现向 Web 服务器发送 GET、POST、PUT、DELETE 等请求,并传递相应参数和数据。
定义基础列表
domains = ["http://yz.chsi.com.cn/", "http://pvp.qq.com/"] visitedDomains = [] links = []
-
domains:一个包含多个字符串元素的列表,表示即将访问的域名列表。其中每个字符串元素都是一个合法的 URL 地址,可以是 HTTP 或 HTTPS 协议。 -
visitedDomains:一个空列表,用于存储已经访问过的域名。 -
links:一个空列表,用于积累从各个页面中提取到的链接地址。
获取单个页面(getPageLink函数)
def getPageLink(domain, page): if not ifBelong(domain, page): return else: pass
函数接受两个参数:一个字符串 domain 和一个字符串 page,分别表示要获取页面的域名和页面路径。
首先,判断页面是否属于给定的域名:
-
如果属于,则继续执行之后的部分。
-
如果不属于,则直接返回。
(其余功能暂未实现)
判断页面是否属于某个域名(ifBelong函数)
def ifBelong(domain, page): return True
(暂未实现)
获取单个域名(getThisDomain函数)
def getThisDomain(domain): global domains, visitedDomains, links response = requests.get(domain) links = getPageLink(domain, response.text) domains += [link for link in links if link not in visitedDomains]
函数接受一个字符串 domain,表示要获取页面的域名。
首先,使用 requests 库发送 HTTP GET 请求,获取指定域名的首页内容。
- 通常情况下,这个内容将会是一个HTML文档,其中包含了若干个链接地址。
然后,调用函数 getPageLink 对该文档进行解析,提取其中的链接地址,并将它们添加到全局变量 links 列表中。
接下来,使用列表推导式遍历 links 列表,并筛选出其中尚未访问过的链接地址:
-
如果某个链接地址已经在
visitedDomains列表中出现过,则忽略它 -
否则,将这个链接地址添加到
domains列表中。
如此便能实现对整个网站的递归遍历。
最后,更新全局变量 visitedDomains,将当前访问过的域名添加到列表中。
循环取出全部域名内容
while len(domains) > 0: lastDomain = domains.pop() getThisDomain(lastDomain) visitedDomains.append(lastDomain)
使用while循环不断地从domains列表中取出最后一个元素lastDomain。然后调用函数 getThisDomain 对该域名进行递归遍历,在遍历过程中,已经访问过的域名会被添加到 visitedDomains 列表中。
当待访问域名列表 domains 为空时,while 循环结束,代表整个网站的遍历完成。此时:
-
全局变量
links中包含所有页面中提取出的链接地址。 -
全局变量
visitedDomains中包含已经访问过的所有域名。
try.py
#encoding:utf-8 a = "a" b = "abcde" print b.replace(a,"z")
纯粹的测试文件,测试将字符串 b 中所有出现的字符串 a 替换为字符常量 z。
wordProcess.py
导入部分
from operator import * import re
-
operator:提供了 Python 内置运算符的对应函数,如加法、乘法、比较等。 -
re:用于进行正则表达式匹配操作。
读取关键词列表并将关键词生成数组
f_key = open('src/key_list.txt') key_list = [] for line in f_key.readlines(): line = line.strip('\n') key_list.append(line) has_num = re.compile(r'[0-9]')
首先,使用内置函数 open 打开文件 'src/key_list.txt',并创建文件对象f_key。
然后,使用 for 循环去除文件对象 f_key 每一行行末的换行符,并将处理好的字符串添加到列表 key_list 中。
最后,使用 re 模块创建一个名为 has_num 的正则表达式对象,用于检测某个字符串中是否包含数字。
- 此正则表达式使用了字符类
[0-9]匹配任意一个数字,因此只要字符串中包含数字,则匹配结果就为真。
将字符串转化为特征向量(changePayload函数)
def changePayload(payload): payload = payload.lower() p_list = [] for word in key_list: while word in payload: start = payload.find(word) end = start + len(word) if (start != 0 and end != len(payload)): if isStrangeChr(payload[start - 1]) and isStrangeChr(payload[end]): p_list.append(word) payload = payload[:start] + payload[end:] else: payload = payload[:start] + payload[end:] elif start == 0 and end != len(payload): if isStrangeChr(payload[end]): p_list.append(word) payload = payload[:start] + payload[end:] else: payload = payload[:start] + payload[end:] else: if isStrangeChr(payload[start - 1]): p_list.append(word) payload = payload[:start] + payload[end:] else: payload = payload[:start] + payload[end:] for i in payload: ascii = ord(i) if (ascii < 48 and ascii != 32 or ascii > 57 and ascii < 65 or ascii > 90 and ascii < 95 or ascii > 95 and ascii < 97 or ascii > 122): p_list.append('ascii' + str(ascii)) if (i != " "): payload = payload.replace(i, "") payload = payload.split(" ") for word in payload: if (word[0:2] == "0x"): p_list.append("16hex") payload.remove(word) for word in payload: if has_num.match(word): p_list.append("normal_num") else: p_list.append("normal_word") return p_list
函数接受一个字符串 payload,表示要进行转化的原始字符串。
首先,将字符串转换为小写形式,并创建一个空列表 p_list 用于存储特征值。
然后,使用两个 for 循环对字符串中的每个字符和关键词进行遍历,并分别进行处理:
-
如果某个字符是特殊字符,则将它替换为相应的特征值
-
如果某个关键词出现在字符串中,则将它从字符串中删除,并将它添加到特征列表中。
接下来,使用字符串方法 split 将字符串按照空格拆分成多个分片,遍历每个分片,检测这些分片内容是否是以 "0x" 开头的十六进制数。
- 如果是,则将
"16hex"添加到特征列表中,并将该单词从字符串中删除。
接着,遍历剩余的单词,检测它们是否包含数字。
-
如果包含,则将
"normal_num"添加到特征列表中。 -
如果不包含,则将
"normal_word"添加到特征列表中。
最后,函数返回特征列表p_list(即字符串payload 的特征向量)。
将文档(训练样本)转化为词集模型向量(wordToVec函数)
def wordToVec(vecList, doc): returnVec = [0] * len(vecList) for word in doc: if (word in vecList): returnVec[vecList.index(word)] = 1 else: print("word is not contained: " + word) return returnVec
函数接受两个参数,分别是一个字符串列表 vecList 和一个字符串列表 doc,其中:
-
vecList表示所有可能的单词(特征)列表。 -
doc则表示待转化的文档。
首先,创建一个长度为 len(vecList) 的全零列表 returnVec,用于存储转化后的词集模型向量。
然后,使用 for 循环遍历文档中的每个单词,并判断它是否出现在可能的单词列表 vecList 中:
-
如果是,则将相应的位置设为 1。
-
如果不是,忽略该单词,并输出一条警告信息:
word is not contained: xxx。
最后,返回得到的词集模型向量 returnVec。
创建文本训练集向量(createDocVec函数)
def createDocVec(payloads, requires): vec = set([]) for doc in payloads: vec = vec | set(doc) for doc in requires: vec = vec | set(doc) return list(vec)
函数接受两个参数,分别是一个字符串列表 payloads 和一个字符串列表 requires。其中:
-
payloads表示所有的异常请求。 -
requires表示所有的正常请求。
首先,创建一个空集合 vec,用于存储所有可能的单词(特征)。
然后,使用 for 循环遍历每个请求(包括正常和异常),并将其中所有出现过的单词添加到集合 vec 中。
最后,将集合 vec 转换为列表,并返回vec。
将文本按照长度进行分类(getWords函数)
def getWords(separateLength): f_pl = open('src/payload.txt') f_norm = open('src/normal_require.txt') pl_list = [] pl_list_short = [] for line in f_pl.readlines(): line = line.strip('\n') if len(line) > separateLength: pl_list.append(line) else: pl_list_short.append(line) norm_list = [] norm_list_short = [] for line in f_norm.readlines(): line = line.strip('\n') if len(line) > separateLength: norm_list.append(line) else: norm_list_short.append(line) return { 'normal': norm_list, 'payload': pl_list, 'normal_shot': norm_list_short, 'payload_shot': pl_list_short }
函数接受一个参数 ``,表示一个阈值,当文本的长度小于等于该值时,就将其视为短文本。
首先,使用open打开两个文件——'src/payload.txt'和'src/normal_require.txt',并为它们创建件对象 f_pl 和 f_norm。
然后,创建四个空列表,分别用于存储长异常请求、短异常、长正常请求和短正常请求。
使用 for 循环遍历 f_pl 中的每一行,将行末的换行符去除,并根据其长度将其添加到相应的列表中。
-
长度大于
separateLength,则插入pl_list中。 -
长度小于
separateLength,则插入pl_list_short中。
同样地,使用 for 循环遍历 f_norm 中的每一行,将行末的换行符去除,并根据其长度将其添加到相应的列表中。
-
长度大于
separateLength,则插入norm_list中。 -
长度小于
separateLength,则插入norm_list_short中。
最后,将四个列表封装成字典,并返回。
判断文本是否是非常规字符(isStrangeChr函数)
def isStrangeChr(chr): temp = ord(chr) if temp > 47 and temp < 58 or temp > 64 and temp < 91 or temp > 96 and temp < 123: return False else: return True
函数接受一个参数 chr,表示要进行判断的字符。
首先,使用ord 将字符转换为相应的 ASCII 码,并将其保存到变量 temp 中。
然后,使用条件语句判断 temp 是否在某个字符范围内:
-
如果
temp在数字、大写字母或小写字母的 ASCII 码范围内,则返回False。 -
否则,返回
True。
这个函数可以判断传入字符是否是“非数字和字母”的字符。
